Description
The Publication Harvester is a software tool that downloads publications from PubMed, stores them in a database, and generates an accurate count of publications for a set of people. The harvester uses a set of possible name variations for that individual, and records the list of authors. The goal of the software is to gather large amounts of data about specific people from PubMed for statistical analysis. It records the people, publications and publication data in a database, and generates reports based on that data.
The Publication Harvester software runs on Windows Vista and XP. It was written in C#, and requires .NET Framework 4.7.2i or later. (This should already be installed if you're running a current version of Windows.)
Documentation
Download
Software downloads:
Quick start:
- If .NET Framework 3.5 isn't installed, either download and install it or (preferred) use Widows Update to install it.
- Download and install MySQL 5.7.
- Download and install MySQL Connector/ODBC 5.1.
- Use the Windows ODBC Administrator (odbcad32.exe) to create an ODBC connection to the MySQL database installed in step #2.
- Download the latest version of Publication Harvester, unzip it, and run the installer.
- Run the Publication Harvester from the Start menu.
More detailed installation instructions can be found in the user manual (see below).
The following sample files may be helpful:
Troubleshooting
-
Troubleshooting Your People File
Did the sample input file work for you, but when you put together your own People file you didn't get the results you were expecting? Take a look at this guide to troubleshooting your People file.
-
Trouble Reading Input Files
A few people have reported trouble running the Publication Harvester software. They found that they were getting errors that look like this:
[Microsoft][ODBC Text Driver] Too few parameters. Expected 2.
Could not find installable ISAM
This application has failed to start because msaccess.exe was not found
The instructions in this guide to troubleshooting problems reading input files helped them resolve the problem.
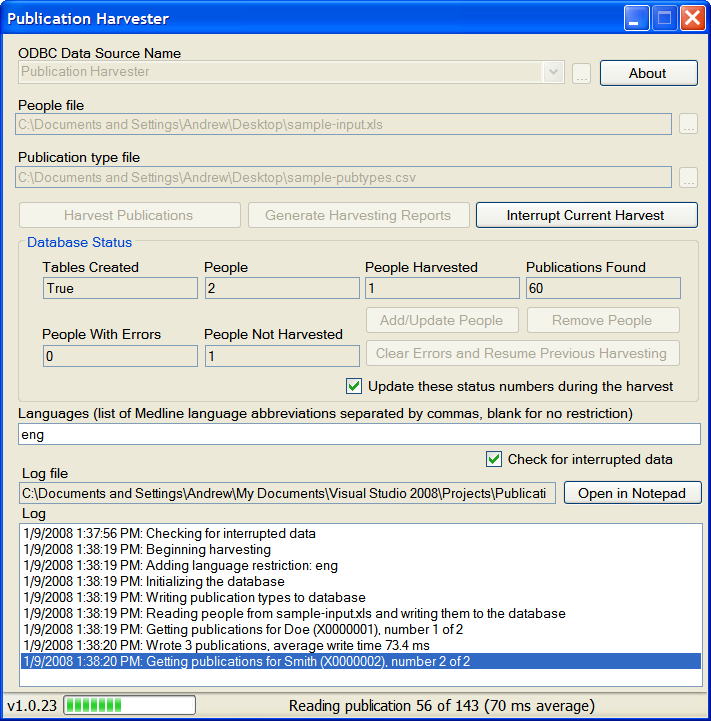
Screenshot
License
Contact Information
Revision history
-
PublicationHarvester 1.1.0.5 -- 31-Aug-2019
See GitHub release page for details
-
v1.0.40 -- 19-Apr-2019
Added support for NCBI API keys (add to api_key.txt in the same folder as PubMed.dll)
-
v1.0.39 -- 16-Apr-2016
Expanded medline search field in database to hold 10,000 characters
-
v1.0.38 -- 28-Sep-2013
Minor bug repair for handling empty publication lists
-
v1.0.37 -- 17-Sep-2013
Fixed bug where empty results get XML error message that's incorrectly parsed as MEDLINE-formatted data with two publiations
Fixed bug on form where 'Clear errors and continue harvest' button sometimes stays disabled, fixed progress bar so it doesn't update for individual publications
-
v1.0.36 -- 16-Sep-2013
PublicationHarvester now uses NPOI to read XLS and XLSX files
Invalid publications (eg. PMID is 0) are now flagged as errors
-
v1.0.35 -- 09-Jun-2012
Log files are now written to %TMP%
-
v1.0.34 -- 06-Jun-2012
Fixed bug caused by null titles, harvest for a person changed to skip error publications without breaking the whole person
-
v1.0.33 -- 13-May-2012
Updated CREATE TABLE commands to use utf8 instead of latin1, added stripping of single- and double-quotes from publication titles in harvest and reading from database
-
v1.0.32 -- 10-Sep-2011
Rebuilt against updated PubMed.dll for changes needed in FindRelated
-
v1.0.31 -- 13-Aug-2011
Added wildcards to names, made some optimizations
-
v1.0.30 -- 29-Aug-2010
Fixed error due to permissions problem in settings
-
v1.0.29 -- 18-Aug-2010
Rebuiltd with .NET 4.0
-
v1.0.28 -- 13-Jan-2009
Fixed memory issues that caused problems with large input files
-
v1.0.27 -- 07-Jan-2009
Updated to support MySQL 5.1
-
v1.0.26 -- 01-Sep-2008
Changed CSV reader to our own CSVReader
-
v1.0.25 -- 15-May-2008
Made a small change to avoid out of memory exceptions on very large transition files
-
v1.0.24 -- 10-Jan-2008
Fixed bug where people with no publications were logged as errors in the database.
-
v1.0.23 -- 09-Jan-2008
Added checkbox to disable check for interruptions, which can take a very long time on huge databases. Fixed error handling to deal with intermittent server problem at NCBI server, and also give better warnings about people without publications in the log.
-
v1.0.22 -- 08-Dec-2007
Changed the DSN so it's no longer read from the registry on startup, and removed redundant checks for interrupted data (because checking for interrupted data can take a very long time on huge databases).
-
v1.0.21 -- 24-Oct-2006
Added support for multiple languages
-
v1.0.20 -- 13-May-2006
Fixed minor glitch that caused error messages to be slightly garbled
-
v1.0.19 -- 16-Apr-2006
Fixed bug that caused out-of-memory exceptions for very large Medline results.
-
v1.0.18 -- 15-Apr-2006
Added feature to add rows for PeoplePublications for any person with the same names and search query (for performance reasons).
-
v1.0.17 -- 22-Mar-2006
Added "update database status" checkbox and buttons for people file maintenance
-
v1.0.16 -- 22-Mar-2006
People file can now be read either from Excel or CSV file
-
v1.0.15 -- 13-Mar-2006
Added a performance enhancement to benefit another project (Colleague Generator)
-
v1.0.14 -- 01-Mar-2006
Fixed a minor bug in reports
-
v1.0.13 -- 19-Feb-2006
Modified reports to allow the user to specify which sections to include in the People report
-
v1.0.12 -- 31-Jan-2006
Added "About" box
-
v1.0.11 -- 29-Jan-2006
Added override first publication type to pubtypes CSV file. (See section 2.1.3 of the software requirements specification.)
-
v1.0.10 -- 27-Jan-2006
Fixed bug in MeSH Heading report.
We gratefully acknowledgement is given to the financial support of the National Science Foundation (Award SBE-0738142).